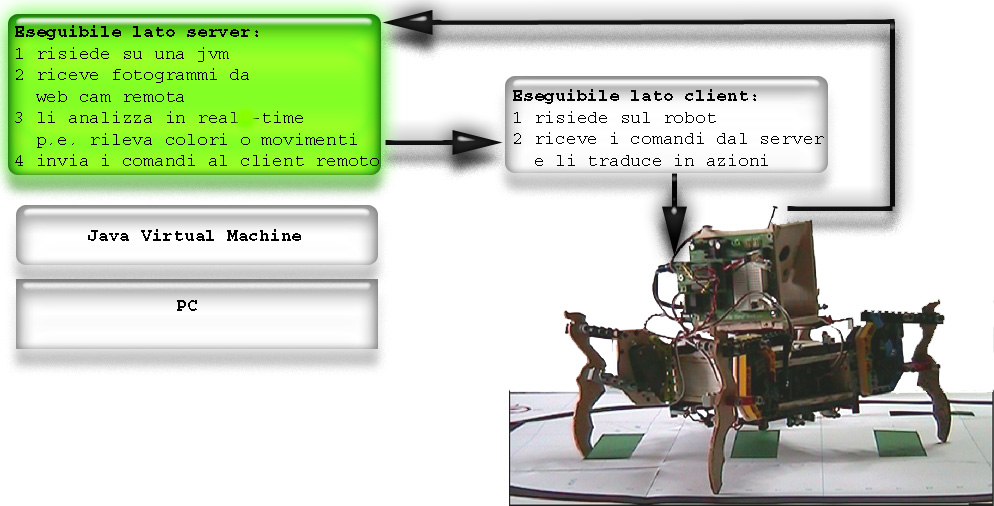

::introtext::
Un processo è costituito dall’immagine binaria di un programma caricato in memoria centrale (detta sezione testo), da un program counter ad esso associato, che ne identifica la prossima istruzione da eseguire, dal contenuto dei registri del processore, dalle sue variabili locali contenute nel suo stack e dalle sue variabili globali contenute nella sua sezione dati.
::/introtext::::fulltext::
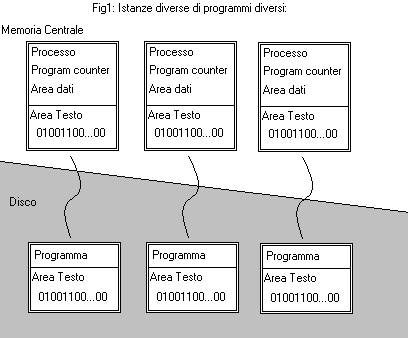
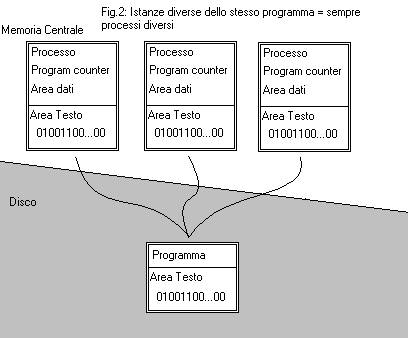
Tutto questo rende un processo molto diverso dal programma (che lo “descrive”) che si trova memorizzato sul disco, quest’ ultimo, infatti, è un’entità statica che non svolge alcun lavoro. Un processo è, invece, un entità dinamica che cambia il suo stato durante la sua esecuzione e che svolge un lavoro, spesso in cooperazione con altri processi che possono essere istanze di programmi diversi (fig.1), o istanze dello stesso programma (fig.2)(ma anche in questo caso i processi sono entità diverse perché anche se hanno tra loro in comune la sezione testo hanno program counter, stak, e sezioni dati distinte e separate).
Stati di un processo e PCB
Come accennato precedentemente, un processo è un entità dinamica che muta il suo stato durante la sua esecuzione, esecuzione che ha un inizio e una fine. Un processo può avere molti stati intermedi tra il suo caricamento in memoria e la sua deallocazione dal sistema, e il numero di questi stati viene deciso in fase di progettazione del sistema, ma in genere sono i seguenti:
- New – Quando il processo viene caricato in memoria, cioè creato (per esempio a seguito dell’invocazione del nome del programma o della creazione di un processo figlio mediante l’uso di apposite system call che possono fare in modo che il figlio abbia una copia locale dello spazio di indirizzi del processo padre o sostituisca il suo spazio con nuovi dati completamente diversi da quelli del padre)
- Ready – Il processo entra in questo stato tutte le volte che attende che il S.O. gli assegni la cpu. Un processo è in Ready quando è pronto per eseguire un CPU-Burst ovvero ha delle computazioni da far fare alla cpu. Può entrare in Ready nei seguenti casi: A) Dopo la sua creazione, se è andata a buon fine. B) Se viene tolto d’autorità dal S.O. dalla cpu mentre la stava ancora utilizzando (a seguito di un interrupt) e quindi vuole ancora usarla. C)Dopo aver concluso un operazione di I/O o dopo aver atteso un evento.
- Running – Un processo si trova in questo stato quando sta usando la cpu. Entra in questo stato sempre dopo la fase di Ready a seguito di un dispatch. Un dispatcher è un modulo del S.O. che ha il compito di gestire il context switch, più il passaggio dal modo kernel al modo utente (per impedire al processo di eseguire istruzioni privilegiate), il salto alla giusta posizione della sezione testo, puntata dal program counter. In un sistema monoprocessore, un solo processo per volta può trovarsi in stato di running e anche se all’utente sembra che tutti i suoi processi stiano lavorando, uno solo di essi in un dato istante sta usando la cpu. Questa illusione dei processi che lavorano contemporaneamente viene data all’utente perché in un ambiente multiprogrammato il S.O. commuta con elevata frequenza la cpu tra i vari processi che sono in ready, facendoli avanzare tutti un po’ per volta. Tale lavoro viene gestito dal S.O., che deve per ogni commutazione: 1) salvare lo stato attuale del processo in esecuzione, 2) caricare lo stato del nuovo processo, 3) effettuare operazioni di gestione memoria. Tutto questo è tempo sottratto alle computazioni dei processi è si chiama tempo di context switch (cambio di contesto).
- Waiting – Quando il processo attende che si verifichi un evento come il completamento di un operazione di I/O o la fine del lavoro di un suo processo figlio.
- Terminated – Quando il processo viene deallocato perché ha finito il suo lavoro. In questo caso il processo è terminato regolarmente. Ma può anche venir eliminato dal sistema perché il processo in questione è figlio di un processo che è stato deallocato (è la politica del sistema non prevede l’esistenza di processi orfani) oppure il processo ha eseguito un operazione considerata dal sistema illecita (come accedere a locazioni di memoria che si trovano fuori dallo spazio a esso allocato).
Essendo i processi oggetti molto diversi tra loro, sia per “forma” (il lavoro che svolgono) che per “consistenza” (la loro dimensione in memoria) un sistema operativo può gestirli in maniera conveniente solo se usa un oggetto che li rappresenta e che gli consente di avere tutte le informazioni necessarie come il suo stato, il suo numero identificativo univoco, il suo program counter, i suoi registri e altre informazioni memorizzate in una struttura dati tutto sommato piccola, almeno se confrontata con il processo al quale si riferisce.
Questo oggetto viene chiamato Process Control Block o PCB.
Il PCB ha anche un puntatore ad altri oggetti del suo tipo, per poter formare con essi delle code di PCB, usate dagli scheduler che vengono descritti più avanti.
Processi cooperanti e comunicanti
Uno degli aspetti più affascinanti della programmazione di un S.O. o dei processi che in esso “vivranno” è la possibilità di realizzare processi specializzati in determinati compiti e fare in modo che essi cooperino tra loro, comunicando, per risolvere problemi più ampi e generici.
Naturalmente i processi restano tra loro concorrenti, cioè competono per usare la cpu e tutte le altre risorse, e se a questo si aggiunge che per essere cooperanti i processi devono anche condividere variabili, file o altre strutture dati, appare evidente che la complessità della programmazione aumenta.
Aumenta perché come progettisti del sistema dobbiamo fornire ai processi un ambiente che non solo consenta, ma che supporti la cooperazione, per esempio fornire meccanismi di comunicazione nativi del sistema, e come progettisti dei processi dobbiamo prevedere metodi di sincronizzazione sull’accesso ai dati condivisi, per evitare problemi di incoerenza e inconsistenza degli stessi, usando strumenti del sistema operativo o progettandone di nostri (un esempio è quello del processo produttore che memorizza l’informazione creata in un buffer Condiviso con un’ processo consumatore che invece usa l’informazione).
Un processo è detto cooperante se influenza o può essere influenzato da altri processi, ovviamente, se un processo non condivide dati con altri processi e non può influire ne essere influenzato è detto indipendente.
IPC
Per poter cooperare, i processi devono poter comunicare. Il S.O. deve fornire dei meccanismi noti come IPC (interprocess-comunication) attraverso i quali i processi possono scambiarsi dei messaggi che di solito usano per sincronizzare il proprio lavoro (vedi esercizio degli attori e del regista che usano mailBox per comunicare). La struttura di base di un IPC deve fornire almeno le primitive send(msg) e receive(msg) ma, a seconda dell’implementazione, è possibile trovare un livello di dettaglio maggiore, come per esempio altri metodi che inviano non un messaggio ma la conferma del ricevimento di un dato messaggio, o altre primitive che possono essere considerate utili.
In generale, però, se due processi vogliono comunicare, occorre che un terzo oggetto, un canale di comunicazione, esista. Per implementare questo oggetto, occorre stabilire alcune specifiche fondamentali. Tra le più importanti scelte progettuali rientrano quelle che stabiliscono se:
- I canali tra i processi vengono allocati dal S.O. e i processi li usano per depositare/prelevare i messaggi (in questo caso il canale esiste finché è in esecuzione il sistema), oppure un processo (server) crea i canali e uno o più processi (client) li usano (in questo caso se il server esce dal sistema anche i canali che ha creato vengono deallocati, e se c’è ancora un client che tenta di accedervi, si ha una situazione d’errore. Occorre in questo caso gestire delle condizioni d’errore o d’eccezione).
- Un canale può essere bidirezionale ( P1 spedisce e riceve da un canale condiviso con P2) o unidirezionale (su un canale un processo può solo spedire e l’altro solo ricevere ), associato a una sola coppia di processi (il canale tra P1 e P2 non può avere altri processi collegati) o essere condiviso tra più processi (P1 spedisce i messaggi su un canale e P2 o P3 o P4, lo leggono. Sorge il problema di stabilite se chi ha letto il messaggio è il destinatario desiderato da P1, che potrebbe, per saperlo, attendere una “ricevuta di ritorno” ovvero una conferma dal ricevente prima di inviare altri messaggi o procedere con il lavoro).
- La comunicazione tra i processi è diretta (P1 comunica con P2 specificando il suo riferimento, P1 quindi conosce, perché lo nomina, P2) o indiretta (P1 non sa nulla di P2 e deposita i messaggi in una mail box dove P2 li preleverà).
Thread
A volte capita che un processo abbia la necessità di avere al suo interno più “oggetti capaci di svolgere del lavoro in autonomia” (tra poco verranno chiamati con il loro giusto nome) specializzati in un solo compito (come la ricerca di un record in un database), o ognuno specializzato in un compito specifico (come in un programma per guidare un robot dove all’interno di questo processo esiste un “oggetto” che si preoccupa di catturare gli eventi di un sensore di contatto mentre un altro, contemporaneamente, (cioè in esecuzione concorrente) si occupa di far muovere i motori). Tutti questi “oggetti che svolgono dei compiti in maniera concorrente e cooperante”, se venissero gestiti come processi tradizionali, sarebbero troppo pesanti per il particolare scopo che si intende raggiungere perché ognuno di essi avrebbe un proprio spazio di memoria privato e molti dati sarebbero duplicati inutilmente. Inoltre, verrebbero gestiti (quindi schedulati) dal S.O. che per farlo passerebbe dal modo utente al modo monitor con conseguente contex switch (comprensivo di operazioni di gestione della memoria visto che ogni processo ha un proprio spazio di memoria diverso).
In questi casi particolari possono essere usati i lightweight process o thread.
Un thread è definito LWP (processo leggero) perché è l’unità di base dell’utilizzo della cpu e consiste solo di un program counter, di registri e del suo stack, ma condivide con altri thread sia il segmento di memoria dei dati che quello di testo, ovvero l’ambiente di esecuzione, che altri non è che un processo tradizionale e che prende in questo caso il nome di task
Quindi un task è un processo tradizionale all’interno del quale sono in esecuzione concorrente dei thread (anche uno solo) che condividono tra loro tutto ciò che è allocato al task nel quale si trovano.
Intuitivamente appare già chiaro che il S.O., quando si preoccuperà di gestire il task, effettuerà dei context switch tradizionali, ma quando gestirà i thread in esso esistenti, si avrà un context switch molto meno costoso perché si tratterà di effettuare solo la copia dei registri del tread sulla cpu e il salto alla giusta posizione del programma del thread, ma nessuna operazione di gestione della memoria verrà eseguita che resta la stessa anche per il nuovo thread.
Si potrebbe immaginare un task come un mini sistema operativo specializzato nel gestire i thread anziché i processi, ma solo quelli, perché poi, ogni system call() dei thread o del task verrà valutata e nel caso eseguita dal S.O. sottostante (a meno che il S.O. non fornisca strumenti particolari come descritto fra breve).
Naturalmente anche e soprattutto per i thread valgono le regole di sincronizzazione dell’accesso ai dati condivisi usando i lock sugli oggetti e la politica delle sezioni critiche.
Segue un esempio che può illustrare i vantaggi dei thread in alcune situazioni particolari:
Esempio : Supponiamo di aver realizzato un’applicazione client server dove i client effettuano delle richieste al server, e quest’ultimo le soddisfa ricercando dei dati in un database.
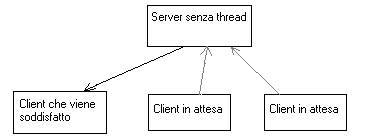
Se il server è un processo senza thread inizia, la ricerca e i nuovi client devono attendere che la ricerca attuale termini prima di vedere soddisfatta la loro, come nella figura seguente.
Se il server è invece un task con più thread (magari allocati dinamicamente), al primo thread viene assegnato il compito di effettuare la prima ricerca, nuovi client verranno soddisfatti “contemporaneamente” perché alla loro richiesta verrà allocato un nuovo thread che ricercherà i dati in maniera concorrente agli altri thread già in esecuzione, essendo la ricerca un’operazione di sola lettura, sullo stesso database possono agire più thread contemporaneamente, come nella fig. seguente.
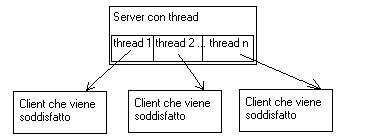
Ma un sistema operativo che voglia supportare i thread, deve prima di tutto stabilire come essi devono essere implementati, se a livello utente o a livello kernel.
I sistemi più recenti sono stati sviluppati per gestire i thread a livello utente, a livello kernel o entrambi.
Il supporto dei thread a livello utente viene fornito dal sistema offrendo al programmatore delle librerie o package che contengono delle system call “speciali”. Queste system call possono essere usate per realizzare dei task che si occupano dei thread senza mai passare in modalità kernel. Un task, può, in questo ambiente, schedulare personalmente i propri thread senza far intervenire il S.O. e risparmiando quindi ulteriore tempo (il context switch “leggero”). In questo caso realmente un task può sembrare un mini sistema operativo.
Se il sistema invece gestisce i thread solo a livello Kernel, essi vengono schedulati dal S.O. che gli concede lo stesso quanto di tempo che concede ad un processo tradizionale, avendo sì un context switch leggero ma dovendo comunque passare in modalità kernel per la copia dei registri e il salto all’istruzione da eseguire riferita dal program counter.
Quello che segue è un esempio che mette in evidenza i pro e i contro delle due scelte:
Supponiamo di avere un task A che ha 1 thread al suo interno e un task B che ha 100 thread al suo interno ecco cosa accade se:
- Il sistema gestisce i thread a livello utente: ogni task (che è un processo) ottiene dal S.O. lo stesso quanto di tempo di cpu, quindi il processo A in un quanto esegue un thread, il processo B il quanto di tempo lo deve dividere fra 100 thread, quindi il task A avrà prestazioni 100 volte superiori. (perché il suo thread avrà il 100% del quanto contro il 10% di ogni thread di B)
- Il sistema gestisce i thread a livello Kernel: ogni thread di un task verrà schedulato dal S.O. il task B verrà schedulato 100 volte ottenendo la cpu 99 volte in più del task A.
Molti sistemi quindi supportano entrambe le modalità.
I thread nei linguaggi di programmazione
Come un S.O. supporta l’esistenza dei thread all’interno dei task, anche i linguaggi di programmazione dovrebbero fornire degli strumenti adatti alla loro progettazione. I più evoluti in questo senso sono i linguaggi orientati agli oggetti come il C++ e il Java, tanto per citare i più noti.
Tuttavia tra i due il C++ offre lo svantaggio di non fornire come tipo nativo del linguaggio un oggetto thread e per usarlo all’interno dei nostri programmi dobbiamo ricorrere a librerie di terze parti come la VCL della borland o altre di altri produttori (MS ecc.). Ovviamente queste librerie non sono tra loro compatibili e dobbiamo scegliere da che parte stare. Il java invece, fornisce un’enorme quantità di classi (oggetti) già pronti per l’uso tra cui i thread. In Java infatti realizzare un thread è semplice come dichiarare un Integer, ciò che invece occorre fare con attenzione è progettarne il comportamento, specie se i nostri thread sono cooperanti.
Esistono due modi in Java per fare di una nostra classe un thread:
- Estendere la classe base (superclasse) Thread che java ci mette a disposizione;
- Oppure implementare l’interfaccia Runnable che ci viene fornita dal linguaggio.
La scelta se usare il primo o il secondo modo è lasciata a noi sulla consapevolezza però che Java non consente l’ereditarietà multipla ovvero la possibilità che ha una classe di estendere contemporaneamente più di una superclasse. Quindi se la nostra classe sta già estendendo un’altra classe, non possiamo contemporaneamente derivare anche la classe Thread. Osserva la figura seguente:
- La classe A definisce un metodo Draw() che disegna un cerchio;
- La classe B estende A e ne eredita il metodo Draw, quindi B.draw() disegna un cerchio proprio come farebbe A
- La classe C estende A ma sovrascrive il metodo draw() che disegna un triangolo, quindi C.draw() disegna un triangolo.
- La classe D estende contemporaneamente sia B che C e non sovrascrive il metodo draw. Ora D.draw() realizza un cerchio (come B.draw()) o un triangolo (come C.draw()) ?
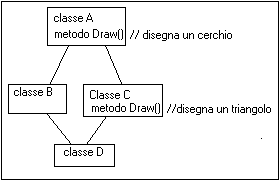
Questo schema prende il nome di configurazione a diamante (e non è scorretta anzi) è si può verificare se il linguaggio consente l’ereditarietà multipla come il C++. Molti programmi sono stati scritti in questo modo, e funzionano alla perfezione perché il C++ fornisce l’operatore :: che consente di specificare a quale delle superclassi ci si vuole riferire.
In Java invece questo operatore non esiste perché, come scelta progettuale ben precisa, l’ereditarietà multipla non è consentita. Questo perché un programmatore “distratto” potrebbe usare male sia un operatore del genere, sia le caratteristiche del “diamante”, aspettandosi cioè un certo comportamento dal suo programma e ottenendone un altro, ma stiamo parlando di un programmatore “distratto”.
Java quindi non ti fa “sbagliare” neanche se lo vuoi se lo vuoi fare apposta, ed è un bene o un male a seconda del programma che vuoi realizzare. Ma mette comunque a disposizione dei programmatori degli strumenti che fanno sì che le caratteristiche di una classe derivino da più oggetti preesistenti. Nel nostro esempio la classe D vuole estendere la classe B, lo può fare ma non può contemporaneamente estendere la classe C. Però se C venisse implementata come interfaccia allora D estenderebbe B e implementerebbe C come nella figura seguente:
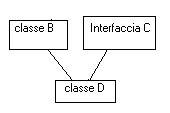
Le interfacce sono classi che non possono essere istanziate, perchè non sono implementate, ovvero forniscono solo le firme dei metodi ma non la loro implementazione. Tale implementazione è lasciata alla classe che la estende. Questo garantisce che in una configurazione a diamante in java non può esservi ambiguità. Perche sé il metodo (nel esempio il metodo Draw) esiste, lo si è ereditato dalla superclasse, se non esiste nella superclasse lo si deve implementare al livello corrente di derivazione, altrimenti non si può compilare.
Quindi tornando ai thread con Java, se la mia classe non estende altre classi per implementare un thread basta estendere la superclasse Thread come nell’esempio seguente.:
public class nomeDellaMiaClasse extends Thread { ... }
Se invece la mia classe estende un’altra classe ma vuole essere anche un thread allora devo implementare l’interfaccia Runnable es.:
public class nomeDellaMiaClasse extend unAltraClasse implements Runnable { … }
Come i processi, anche i thread hanno vari stati, e nello specifico di java gli stati che un thread può assumere (nella JVM) sono:
- New – Il thread è in questo stato subito dopo la sua inizializzazione (da non confondere con la sua dichiarazione che non alloca memoria per il thread ma per il suo riferimento, ne con la definizione che non alloca memoria ma ne definisce solo la struttura, es: public class Produttore extend Thread {…} e una definizione, mentre Produttore p; è una dichiarazione, ma Produttore p=new Produttore() e una inizializzazione e solo in questo caso p è in stato di New).
- Runnable – Un thread è in questo stato mentre esegue il suo metodo run (che noi come programmatori dobbiamo realizzare). Il metodo run viene eseguito dopo l’invocazione del metodo start() (che possiamo se vogliamo sovrascrivere).
- Blocked – Un thread può essere temporaneamente sospeso dalla cpu dal task o da se stesso invocando una sleep() o altri metodi della classe.
- Dead – Un thread entra in questo stato subito dopo l’invocazione del metodo stop () o subito dopo aver terminato il metodo run (), nella JVM i thread in dead vengono de allocati quando necessario usando una tecnica di recupero dello spazio inutilizzato nota come garbage collection (questo vale per tutti gli oggetti, infatti, in java si può allocare dinamicamente la memoria definendo per un oggetto un costruttore, ma non è necessario de-allocarla definendo un distruttore, farà tutto la JVM).
Comments powered by CComment